
Una arquitectura de base de datos se refiere a la estructura y diseño de cómo se almacenan, gestionan y acceden a los datos en un sistema de gestión de bases de datos (DBMS). Esta arquitectura establece cómo se relacionan y comunican los componentes del sistema, cómo se gestionan los datos y cómo se optimiza el rendimiento.
Tipos de arquitecturas de bases de datos (Tier 1, Tier 2 y Tier 3)
La base de datos va a formar parte de una arquitectura más compleja, tanto a nivel de hardware como de software, por lo que no todas las configuraciones valen, y cada una nos aportará cosas diferentes. Conceptos como escalabilidad, capacidad, seguridad y usabilidad son clave para elegir una arquitectura u otra. Las tres más conocidas son las tier 1 (Single Tier Architecture), tier 2 y tier 3.
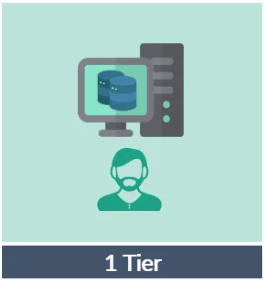
Arquitectura Tier 1 (Single Tier)
Se trata de una arquitectura donde servidor, cliente y base de datos residen en la misma máquina. Aquí se alojarán la aplicación, los datos, el DBMS y la interfaz, todo en el mismo sitio. Puede resultar útil para entornos de pruebas, pero no es lo habitual en producción.
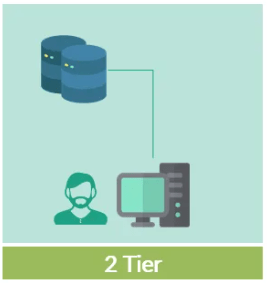
Arquitectura Tier 2 (Cliente–Servidor)
La típica aplicación cliente-servidor. La capa de presentación de datos se encuentra en otra máquina o máquinas, independiente del servidor donde reside la base de datos, llamado tier 2. De esta forma, la base de datos no está expuesta a los servicios de los clientes y podemos tener varios usuarios conectados a la base de datos.
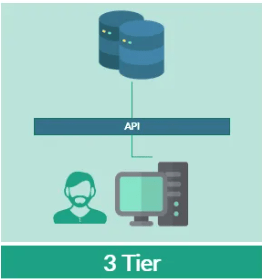
Arquitectura Tier 3 (Presentación, Lógica y Datos)
Separamos la capa de presentación (los usuarios), la capa de aplicación, que hace de intermediador comunicando las peticiones de los usuarios con la base de datos, y la capa con la base de datos en otro servicio donde estarían definidas las relaciones entre las tablas de las bases de datos. Cabe destacar que en la capa de aplicación es donde se define la lógica de comunicación entre usuario y BD, y por consiguiente abstrae al usuario de la comunicación con la BD. Es con esta pieza de software (middleware) con quien se comunica, y no con la BD.
Niveles de una arquitectura de base de datos (ANSI-SPARC)
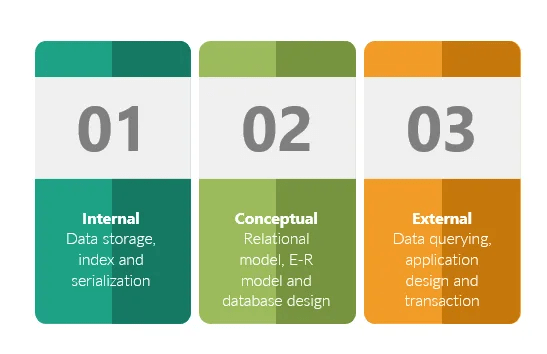
Las bases de datos tienen una arquitectura a tres niveles compuesta por:
- Nivel Interno (Físico): Este nivel se refiere a cómo los datos se almacenan físicamente en el dispositivo de almacenamiento, como discos duros. Incluye detalles sobre la estructura de almacenamiento, la organización de datos en bloques, la gestión del espacio y la optimización del rendimiento.
- Nivel Conceptual (Lógico): En este nivel, se define la estructura lógica de la base de datos, independientemente de cómo se almacenan físicamente los datos. Se establecen las entidades, relaciones, restricciones y reglas de integridad. Es un nivel de abstracción que describe la base de datos en su conjunto.
- Nivel Externo (de Usuario o de Vista): En este nivel, se crean vistas personalizadas de los datos para usuarios finales o aplicaciones específicas. Cada vista muestra solo la porción de la base de datos que es relevante para el usuario o la aplicación, proporcionando una capa de abstracción y seguridad.
Estos tres niveles forman la base de la arquitectura de base de datos ANSI-SPARC (American National Standards Institute – Standards Planning and Requirements Committee), que busca una separación clara de preocupaciones y una estructura organizada para diseñar y gestionar bases de datos de manera eficiente.
Bases de datos en arquitecturas de microservicios (patrones)
Tradicionalmente se han desarrollado aplicaciones en arquitecturas monolíticas, que básicamente son aquellas que engloban todos sus componentes en un mismo artefacto, es decir, en una unidad indivisible. Este enfoque es muy sencillo de comprender e implementar, pero presenta serios problemas de escalabilidad, ya que cada vez se van añadiendo más componentes, los cuales se encuentran muy acoplados, y si falla alguno es muy fácil que contagie al resto. Además, otra problemática importante que presenta este tipo de arquitecturas es que los recursos hardware son compartidos.
A raíz de estas dificultades surgen las arquitecturas de microservicios, que buscan dividir las aplicaciones en un conjunto de servicios independientes y autónomos. Cada microservicio se centra en realizar una función concreta, ejecutándose en procesos separados y comunicándose con otros mediante sus APIs.
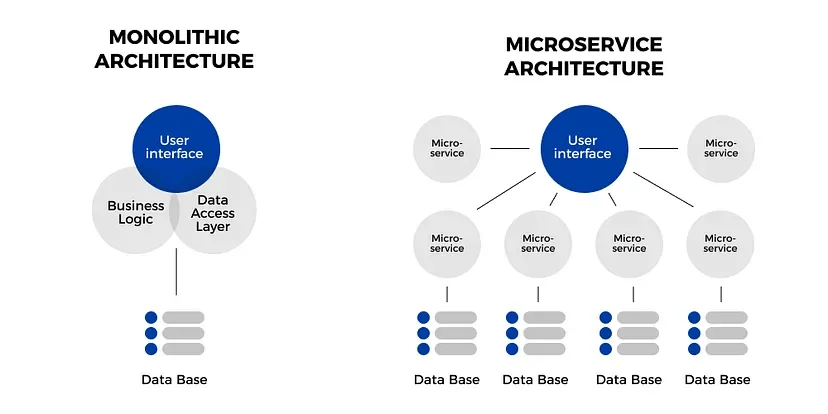
Existen diversos patrones de diseño para este tipo de arquitecturas como el database por servicio, los API Gateway Patterns, CQRS o Saga. El más habitual es el database por servicio, donde tendremos aislada cada base de datos, trabajando de forma independiente, por lo que fallos en uno de los servicios no van a afectar a los otros, permitiéndonos escalar la BD de forma más sencilla. De esta manera pasamos de tener una base de datos masiva, a tener varias bases de datos más pequeñas. Y no solo eso sino que podremos elegir el tipo de base de datos en función de las necesidades que tengamos en cada servicio.
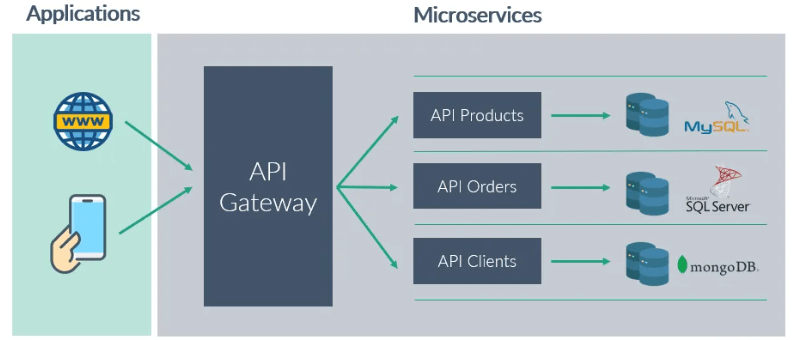
Bases de datos en contenedores (Docker y Kubernetes)
Para poder implementar una arquitectura de microservicios, se podría desarrollar cada servicio dentro de un servidor físico. Sería buena opción en cuanto a aislamiento, puesto que cada uno cuenta con recursos dedicados y el fallo de uno no afectará a los otros.
Aún así, no sería una solución eficiente, puesto que los costes aumentan considerablemente, ya que como hemos visto en este artículo, una arquitectura Tier 3 ya implica 2 servicios desplegados, y eso únicamente para una base de datos. Imagínate una empresa grande que tiene decenas de bases de datos. No es viable.
Para ello acudimos a la virtualización, que no es más que desplegar máquinas virtuales o contenedores dentro de otras máquinas, de tal manera que podamos simular varios servidores dentro de un único servidor físico.
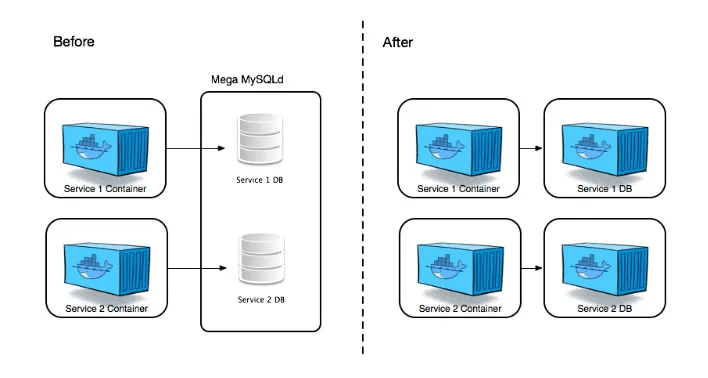
Tradicionalmente se han estado utilizando máquinas virtuales para aislar un servicio del otro, hasta que aparecieron en escena los contenedores, con Docker y Kubernetes. Los contenedores aportan una mayor ligereza, portabilidad y eficiencia de recursos. Por lo que las aplicaciones se empezaron a desplegar en contenedores. Por tanto, en este tipo de arquitecturas se despliegan varios contenedores dentro de una misma máquina física, siempre y cuando la capacidad de la máquina sea suficiente como para aguantar todos estos servicios.
Con Docker podemos definir en un único archivo (Dockerfile) cómo queremos que sea la base de datos que queremos desplegar, que sistema operativo queremos que lleve por debajo, tipo de base de datos, qué puertos usaremos, etc… simplificando considerablemente la puesta en producción. En estos temas se profundizará más en el apartado de Docker.
Arquitectura Lambda vs Kappa
Hemos visto cómo es una arquitectura básica de una base de datos, e incluso cómo se integra con otros servicios. Vamos a aproximarnos a un caso más realista, donde veremos cómo encaja una base de datos dentro de un ecosistema Big Data. Para ello, primero compararemos los dos tipos de arquitecturas principales: Lambda y Kappa. Se trata de dos enfoques diferentes para procesar y analizar datos en tiempo real.
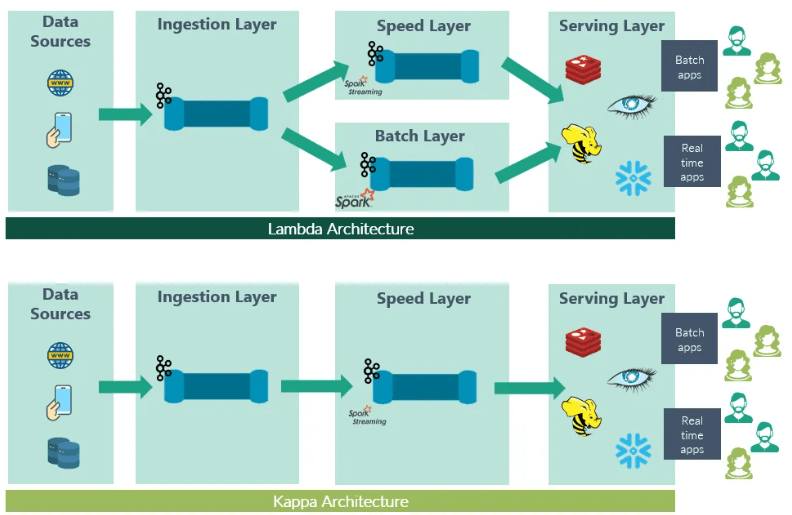
En ambas arquitecturas vamos a tener una serie de fuentes de datos que vuelcan su información en un entorno de Big Data como puede ser un Data Lake. Esta ingesta la pueden realizar sobre una base de datos relacional, no relacional o a través de una cola de mensajes que se reciban en real time. Donde realmente difieren ambas arquitecturas es en la siguiente etapa del pipeline de procesado de datos, como veremos a continuación.
Arquitectura Lambda
En la arquitectura Lambda, se procesan los datos en dos flujos distintos, lo que permite abordar tanto datos históricos como eventos en tiempo real. Los datos se almacenan en dos capas diferentes: una para almacenamiento de datos en bruto y otra para almacenamiento de datos listos para el análisis en tiempo real. Esto implica la ejecución de tareas de procesamiento periódicas para transformar los datos en bruto en datos útiles. Sin embargo, esta estructura dual puede introducir cierta complejidad en el sistema.
Arquitectura Kappa
La arquitectura Kappa simplifica las cosas al procesar datos solo en tiempo real. Los datos se ingieren en un flujo constante y se transforman a medida que avanzan. No hay necesidad de procesamiento batch o capas de almacenamiento separadas. Esto se logra almacenando los datos en un flujo continuo, como un sistema de mensajería, y transformándolos a medida que se ingresan. Esta simplicidad es la característica distintiva de la arquitectura Kappa.
Comparativa de ambas arquitecturas
Vamos a analizar los aspectos fundamentales a tener en cuenta a la hora de elegir una arquitectura u otra.
- Complejidad: La arquitectura Lambda puede ser más compleja debido a las múltiples capas de procesamiento y la integración de resultados. La arquitectura Kappa simplifica el flujo de procesamiento al tener un único flujo en tiempo real.
- Latencia: La arquitectura Kappa tiene una menor latencia debido a que los datos se procesan continuamente en tiempo real, sin la necesidad de procesamiento batch. La arquitectura Lambda puede tener una mayor latencia debido al procesamiento batch en la capa de procesamiento por lotes.
- Mantenimiento y administración: La arquitectura Kappa puede ser más sencilla de mantener y administrar debido a su enfoque simplificado con un solo flujo de procesamiento en tiempo real. La arquitectura Lambda puede requerir un mayor esfuerzo de configuración y gestión debido a las múltiples capas de procesamiento.
- Escalabilidad: Ambas arquitecturas son escalables, pero la arquitectura Kappa se destaca en términos de escalabilidad, ya que se basa en sistemas distribuidos y permite aumentar su capacidad de una forma sencilla.



